Preston Says: I asked Dan McClary for a big favor recently: use his general UNIX knowledge and graduate-level statistics voodoo to produce a report highlighting performance characteristic differencess between OpenSolaris ZFS and Linux RAID5 on a common, COTS hardware platform. The following analysis is his work, reformatted to fit your screen. You may download the PDF, HTML, graphs and original TeX source here.
A Brief Comparison of I/O Performance for RAIDZ1 and RAID-5 Filesystems
Dan McClary
June 28, 2007
Introduction
The following is a description of results obtained benchmarking I/O performance for two OS/filesystem combinations running identical hardware. The hardware used in the tests is as follows:
- Motherboard: Asus M2NPV-VM.
- CPU: AMD Athlon 64 X2 4800+ Dual Core Processor. 2.5GHz, 2?512KB, 1GHz Bus
- Memory: 4 x 1GB via OCZ OCZ2G8002GK DDR2-800 PC2-6400
- Drives: 4 x 500GB Western Digital Caviar SE 16 WD5000AAKS 7200RPM 16MB Cache SATA 3.0Gb/s
The Linux/RAID-5 combination uses a stock Ubuntu Server Edition installation, running kernel 2.6.19-generic, with RAID-5 configured via mdadm and formatted ext3. The Solaris/RAID-Z1 configuration is a stock installation of Solaris Developer Express Edition with zpool managing the zfs-formatted RAID-Z1 drives. Block size for all relevant tests is 4096 bytes.
Basic I/O testing is conducted using bonnie++ (version 1.03a), tiobench (version 0.3.3-5), and a series of BASH-scripted operations. Tests focus on I/O throughput and CPU usage for operations either much larger than available memory, and very large numbers of operations on small files. All figures, unless otherwise noted, chart mean performance with 2% deviation for large-file operations and 5% for small-file operations. These bounds well-exceed the 95% confidence interval, implying a range of high significance.
Large-File Operations
In dealing sequential reads and writes, particularly of large files, the Solaris/RAID-Z1 configuration displays much higher throughput than the Ubuntu/RAID-5 combination. Latency and CPU usage, however, appear to be higher than in the Ubuntu configuration. The reasons for these disparities are not determinable from the tests concluded, though one might venture that the management algorithm used by ZFS and each systems caching policies may play a part.
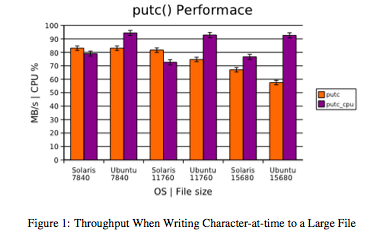
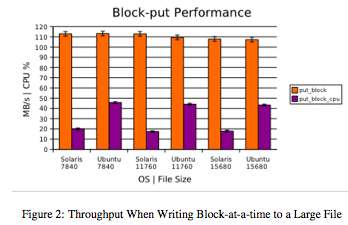
Figures 1, 2, and 3 summarize large-file writing performance in the bonnie++ suite. In large writes, Solaris-ZFS displays marginally higher throughput and occasionally lower CPU usage. However, the disparities are not great enough to make a strict recommendation based solely on large-file writing performance.
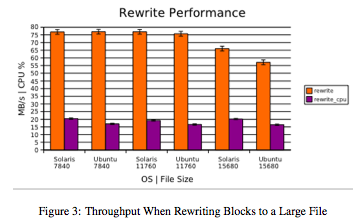
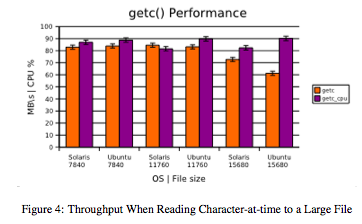
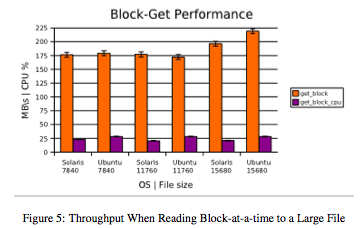
Figures 4 and 5 illustrate throughput and CPU usage while reading large files in the bonnie++ suite. Generally, results are consistent between platforms, with the Ubuntu configuration showing a slight edge when reading 15,680MB files (though with an associated drop in CPU efficiency).
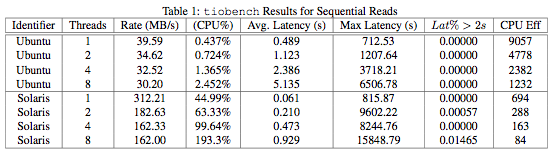
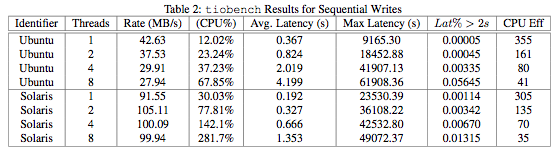
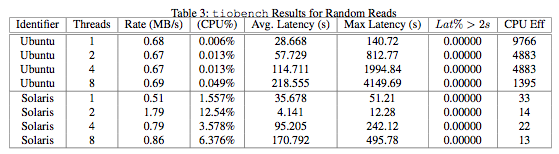
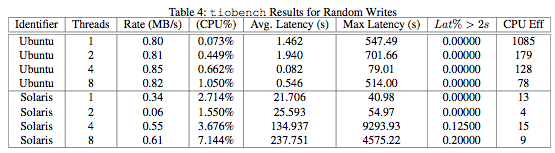
tiobench results for random reads and writes given in Tables 3 and 4 show the Ubuntu/RAID-5 configuration displaying both higher throughput and greater CPU efficiency. However, these results seem somewhat questionable given the results in section §3.
Small-File Operations
In examining the performance of both configurations on small files, both in the bonnie++ suite and from shell-executed commands, the most obvious statement that can be made is that the Solaris configuration displays greater CPU usage. This, though, may not be indicative of poor performance. Instead, it may be the result of an aggressive caching or other kernel-level policies. A more detailed study would be required to determine both the causes and effects of this result. In each test, 102,400 files of either 8 or 4KB were created.
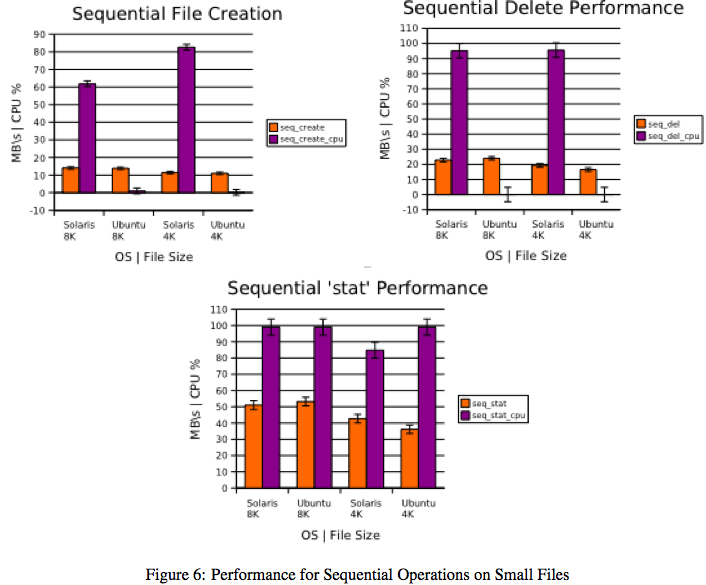
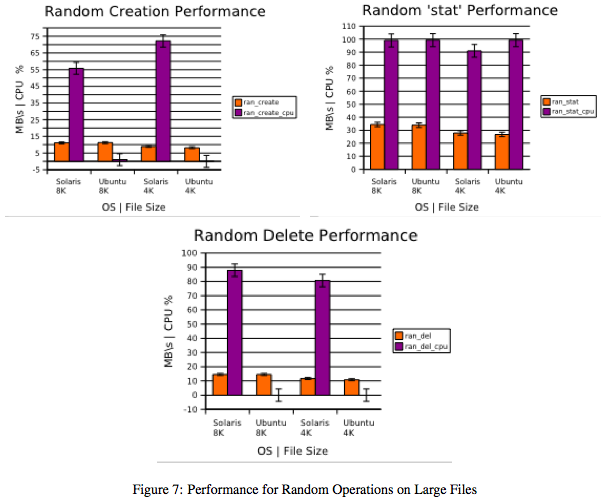
Figures 6(a)-6(c) and 7(a)-7(c) illustrate bonnie++ performance for both configurations. In contrast to the tiobench results, the Solaris configuration generally displays slightly higher throughput (on the order of 1-2MB/s) than its counterpart. However, as previously noted, CPU usage is much higher.
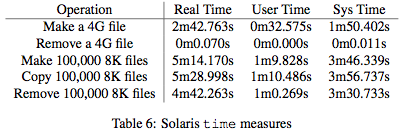
Finally, Tables 5-6 lists measured times as given by the standard Unix command time when measuring command execution. In these results, there are some surprises. The Ubuntu configuration performs somewhat faster when executing a large write (using the command dd). However, the Solaris configuration is much faster when dealing with 100,000 sequential 8KB files. For reference, all file creation is done via dd, copying by cp and deletion by rm.

Conclusions
Few overarching conclusions can be drawn from the limited results of this study. Certainly, there are situations in which the Solaris/RAID-Z1 configuration appears to outperform the Ubuntu/RAID-5 configuration. Many questions remain regarding the large discrepancy in CPU usage for small-file operations. Likewise, the Ubuntu/RAID-5 configuration appears to perform slightly better in certain situations, though not overwhelmingly so. At best, under these default configurations, one can say that overall the Solaris configuration performs no worse, and indicates that it might perform better under live operating conditions. The latter, though, is largely speculation.
Indeed, from the analyst’s point of view, both configurations show reasonable performance. The desire to deploy either configuration in an enterprise setting suggests that significant-factor studies and robust parameter designs be conducted on, if not both candidates, whichever is most likely to be deployed. These studies would provide insight into why the discrepancies in current study exist, and more importantly, achieve optimized performance in the presences of significant uncontrollable factors (e.g. variable request-load).
Preston Says: Thanks for the outstanding work, Dan!